Arvato Financial Customer Segmentation and Propensity to Respond
This is a capstone project to satisfy the the Udacity Data Science NanoDegree. I will analyze demographics data for customers of a mail-order sales company in Germany, comparing it against demographics information for the general population. The goal is to find segments of the general population that will best fit future mailings. Thereby reducing mail to those unlikely to become customers. I will use unsupervised learning techniques to perform customer segmentation, identifying the features of the population that best describe the core customer base of the company.
Then, I will apply the learnings on a third dataset with demographics information for targets of a marketing campaign for the company, and use a model to predict which individuals are most likely to respond into becoming customers for the company. The data that I will use has been provided by partners at Bertelsmann Arvato Analytics, and represents a real-life data science task.
Getting to know the data
The data consists of 366 columns of data for each individual. It includes information outside of individuals, including information about their household, building, and neighborhood.
The data in the project also includes two helper files in .XLS format with information about each attribute in the dataset. One file has information the source of the data and another has information about what each value in the data represents. For intsance:

The big take away here is that nearly all attributes include a value that represents Missing or Unknown. These values will pollute our model training and will need to be converted to a NaN value (or not a number).
Pandas Profile report
One of my favorite tools for EDA is the Pandas Profiling library. This library automates the EDA tasks data scientists take on each day. The report outlines the distrobution of each column, its missing values, its data type and some very helpful tools in categorical columns.
In the real world I would do most of my learning about the data and make many decision here with this html document. However, for the scope of this project, it is difficult to show the process with this tool. Thus, I will create a few visuals to highlight some of the decisions.


Example
In the first visual above in the Profile Report is for the LNR feature, Pandas Profiler has clearly shown that this feature has unique values for all rows and is likely an ID or another type of value that will not help our model. It will be dropped from the dataset before clustering. Profiling shows me the distribution and missing values for each feature. This is very helpful when making decisions on whether a feature must be futher engineered.
Convert Unkown Values to NaN
Give the size of the dataset, perhaps I use a bit of string matching to find each of the attribute’s specific missing value code and programitically replace these values with NaN.
I will first build a list of only attribute and value that can be stored and reused in future data cleaning.
With these data dictionary documents open in Excel, a quick visual scan helped me see that there are basically 4 distinct string values that represent an unknown value: ‘unknown’, ‘unknown / no main age detectable’, ‘no transaction known’, and ‘no transactions known’
First, let’s view the missing values by column currently in the dataset. Here is a view of the frequency of NaN per column.
We are unable to see all column names in the visual, but we can see a decent view of the volume of missing values. This is before we convert the missing or unknown codes. The total number of fields with NaN across all columns and rows is:
33,493,669After using the values file to programitically convert the missing value codes into NaN values we can now see a far greater frequency of NaN per column and certain columns are now showing far more missing values than before.
After this round of conversion the new total number of fields with NaN across all columns and rows is:
51,863,595Now I can see that there are clearly many columns which are missing the majority of values per user. They may need to be removed from the data before using it to train models or make predictions.
Row Based Cleaning
In addition to looking at columns with missing data we should look to see if there are individuals who, row-wise, are missing so much data that I should remove them from the data before training or making predictions.
Next we will look for rows that are missing data. If a single row is missing most of the data fields it won’t help me make predictions.
First I will plot a histogram to see the distribution of missing values per row.
There are 366 columns in the DataFrame. I will count the missing values in each row and look for an obivous pattern.
As our data set was built from serveral sources. It is likely that certain individuals might be missing an entire portion of the columns as they were not matched to that source. This would present a pattern.
First let’s view the distribution of missing day by row.
There are three “shapes” visible in the distribution. The first shape from the left has a steady curve. The next two shapes are skyscraper like spikes in count of individuals who are all missing that same amount of values in the row. The first curved shape to the left indicates that all of these individuals have data present in nearly 300 columns and likely some from all the disparate sources but the gradual curve of fewer and fewer missing data above 300 columns leads me to believe that the remaining data fields are truely not applicable such as "Age_Child_4". Fewer and fewer individuals with have data on a fourth child, becuase they have no fourth child and thus the NaN here is a value.
Alternatively, the large spikes both lead me to believe that individuals in these bins are missing all the data from one or more data sources.
For now, I will remove rows that represent the right most spike (and a little further). The second spike of missing data may present itself as a pattern in it’s value in the future PCA portion. If so, I can re-adjust.
Here is the breakdown of how many rows would be cut if I moved further to the right of the visual:
After left spike: 73,517
Middle ground: 106,189
Before second spike: 154,831
After second spike: 320,824Tough call. 160,000 rows will be lost in order to be sure that each data field is truly represented. In the more strict scenario we would remove 320k rows and be left with only 64% of the data.
In the real world part of this decision would be made by understanding the business case for the value of predicitons in the future. Is it more important to make a less accurate prediction with fewer data, or a more accurate prediction with fewer overall predictions possible in the future due to missing data?
I will start the process by including more rows and set the threshold at 278 columns. Then, drop individual columns with a similar ratio of missing values per row.
Now, that I have dropped all rows with less than 278 fields of data, let’s look at the frequency of missing values per column one more time:
Clearly there was a pattern. The long tail of missing values is now gone.
Final Cut
Now that all missing values are properly converted, and rows that were missing most of their data have been removed. We can make a decision on which columns might simply be missing too much data and need to be removed.
Clearly many of the missing data come from the same D19_* source. These columns will have a negative impact on the model training and should be dropped from the training data and future predictions.
Looking at the visual I can see a sharp cut off and plateau at 23%. I will choose that as the limit and remove all columns with more than that.
Feature Engineering
Next is a very important and challenging portion of the data preparation needed for this project. I will need to identify columns that require transformations. Such as:
- Categorical columns
- Multi-label fields
- boolean
- Ordinal columns
- Date columns
Here I used the HTML file created by the Pandas Profiling tool to visually inspect columns quickly to determine which were categorical versus ordinal. This allowed me to create a file to help determine which columns should be engineered and how.
First, I’ll look at any column with an object datatype.
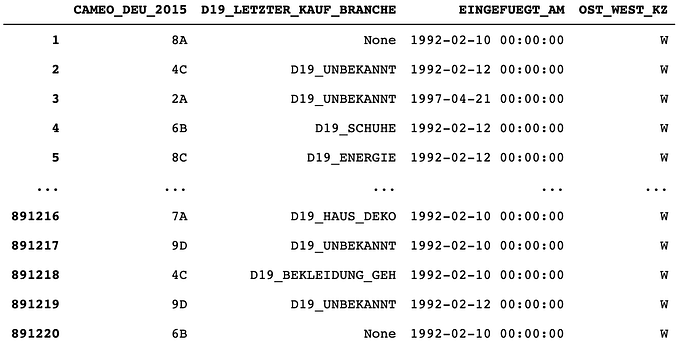
Looks like the EINGEFUEGT_AM column is a date like object. I will start with this one. As long as all values. The meaning roughly translates "inserted" and there is no information in the data attributes file about this column. I don't know what it means, but inserted leads me to possibly believe this is when the data was collected?
Eitherway, if it is going to help our model make predictions it will be better as year and month individually. I convert the column like so.
Next I will look at a categorical column that has been combined. See the image below. I noticed this one by looking through the `Values` .xlsx file and saw that the first value in the number pair represent one category and the second value in the number pair represents another category. For cleaning model training I will separate these values into their own columns to allow for the model to be slightly more general.
Finally, I will take remaining categories and one-hot encode them into a sparse matrix as their current increasing value is not ordinal.
TODO = Show correlation between FEIN and GROS to prove dropping these columns.
The final preparation will be to impute the missing values that I have left in the data. For the upcoming task of Principle Component Analysis and K-Means Clustering we will need all values to be present. For this task I will use the median value for each column to be imputed where values are missing.
All Cleaning tasks in a single function
Finally, I’ll take all of the steps above and create a single cleaning function to perform the same process on our validation data and possible future data. I have added some functionality to skip the imputation step for future scenarios where an particular model may be able to handle NaN values.
Clustering
The main bulk of your analysis will come in this part of the project. Here, you should use unsupervised learning techniques to describe the relationship between the demographics of the company’s existing customers and the general population of Germany. By the end of this part, you should be able to describe parts of the general population that are more likely to be part of the mail-order company’s main customer base, and which parts of the general population are less so.
K-POD
My first trial at clustering included a test of a new algorithm K-Pod. K-Pod allows for K-Means clustering a much faster speeds and handles NaN values in the process. K-Pod handed all 489 columns of data with NaN values in 11 minutes and created a 6 center K-Means cluster. While this was a fascinating test, the current library is not built out for re-use on new datasets and is untested in accuracy. Learn more here:
Principle Component Analysis
Before using more traditional methods of Clustering I can reduce dimensions with Principle Component Analysis. This technique will allow me to speed up our clustering efforts by using far fewer dimensions but maintain the variance in the data.
However, before I can use either of these algorithms I need to scale our data so that certain features don’t over influence the results. I will use Sklearns StandardScaler to scale each feature to a mean of 0 and a standard deviation of 1.
First, we’ll look at the explained variance for an increasing number of components to determine the best compromise of explained variance to efficient computation.
Ideally I would see in this visual a sharp elbow where a large portion of variance in the data could be explained and additional components would not add much. However, here I can see a change in inertia at 50 components. Then the slope of explained variance remains linear until about 250.
Next I will look at the inverse of these with a Scree Plot with the added explained variance for each additional component.
We can see for our visuals above that like many large datasets a few components account for a larger explanation of the variance. However the outliers here account for only about 25% of the total variance.
I have seen some discussion among others about 85% of explained variance being a good baseline needed for accurate predictions, however that would be about 250 dimensions. At 180 dimensions I get to about 75% of variance explained. I will start there.
Loading scores
Component 1
Component 2
Optimal Clusters
Next I will test several Kmeans centers to find a starting point of least SSE versus trainging time
11, 19 or 25?
There are three low points that could make a good starting point for the optimal number of K-Means cluster centers. The balance here will be to look for the lowest distance from each datapoint without growing beyond an efficient computation or loose explainability.
Customer Data comparison
Next I will map the customer data to these clusters to see if our customers over index in any significant manner.
Understanding our clusters
Now that I can see how our customer group differs from the population, I will take a look to determine some individual features that differ.
With 366 different columns of data to start it is too exhuastive to analyse each feature. However, with PCA and our Loading Score visual, we might start with those features that had the largest proportion of the eigenvector in the components that had the greatest explained variance.
Cluster 18
One cluster had more than 25% of our customer population. Cluster 18 is a great example to start to see the features that most qualify our customers.
Lets look at a couple of likely features that will differ from the general population.
MOBI_REGIO — This feature had the highest loading score in the Principle component with the most explained variance. The freature describes moving patterns. Lower numbers are high mobility and high numbers are very low mobility. It is clear the Arvato Customers have lower mobility regionally.
PRAEGENDE_JUGENDJAHRE This is the dominating movement in the person’s youth (avantgarde or mainstream). Lower numbers are older and even numbers skew toward an Avantgarde youth movement.
Clearly the Arvato customer base skews older and more Avantgarde.
KBA13_HERST_BMW_BENZ — In the third Principle Component we can see the highest loading scores are all regarding automobiles and generally those of a luxury class. This feature is the share of BMW & Mercedes Benz within the neighborhood. A score of 5 is high.
PLZ8_ANTG1 — Finally, the number of 1–2 family houses in the neighborhood of the individuals is lower for the customers in Cluster 18
Modeling
Part 2: Supervised Learning Model
Now that I have found which parts of the population are more likely to be customers of the mail-order company, it’s time to build a prediction model. Each of the rows in the “MAILOUT” data files represents an individual that was targeted for a mailout campaign. Ideally, I should be able to use the demographic information from each individual to decide whether or not it will be worth it to include that person in the campaign.
The MAILOUT data has been split into two approximately equal parts, each with almost 43 000 data rows. In the first part, I can verify the model with the TRAIN partition, which includes a column, RESPONSE, that states whether or not a person became a customer of the company following the campaign. In the next part, I will need to create predictions on the TEST partition, where the RESPONSEcolumn has been withheld.
To start I will use the Data Cleaning function created above to clean, and impute data for training.
Then I will test 4 different algorithms with minimal tuning of hyper parameters to get a base line of prediction score. This will help determine which model will be the best place to begin more thorough tuning of hyper parameters.
Model Metrics
All predictions will be scored with an Area Under the Curve calculation. This allows us to balance the True positive rates over the False positive rates. With our predictions a simple binary class this measure will be much more insightful than a simple accuracy
Receiver Operater Characteristic curve (ROC curve) allows us to see the false positive against false negative rate of our classifier. The area under the curve gives us a single metric to compare these results.
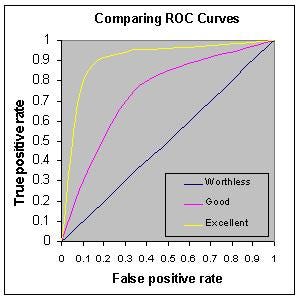
Class Imbalance
In each of the test algorithms I will attempt to correct for our class imbalance. Given this is a marketing message only 1 in 80 individuals responded. Thus, our algorithm could simply learn to choose all 0 and get a high accuracy.
First test, Logistic Regression
Logistic Regression is a basic classifier that is computationally in-expensive once trained and simple to interpret the results if needed. Here is a basic visual of how Logistic Regression works.
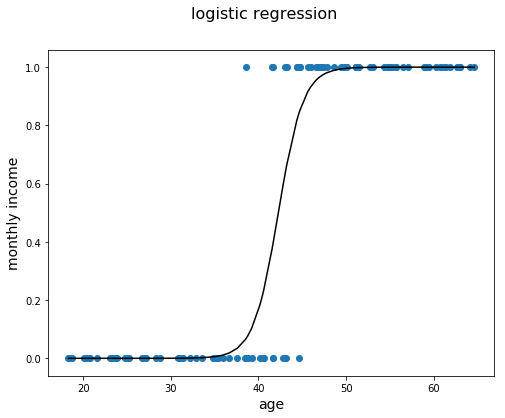
I chose to use just a couple of parameters to give this a quick test. The Sklearn function allows for me to choose a class weight. This can correct for a class imbalance similar to what we have in the dataset.
Score:
Support Vector Machines
This algorithm can be very effective with high dimensional data.
SCORE:
Boosting algorithms
Boosting models train predictors sequentially, each trying to correct its predecessor.
AdaBoost
Or Adaptive Boosting:
- Fit a base classifier like a Decision tree.
- Use that classifier to make predictions on the training set.
- Increase the relative weight of the of the instances that were misclassified
- Train another classifier using the updated weights.
- Aggregate all of the classifiers into one, weighting them by their accuracy.
XGBoost
Or Extreme Gradient Boosting, the objective is to minimize the loss of the model by adding weak learners using a gradient descent.
Tuning XGBoost
It seems AdaBoost and XGboost are similarly working better than the other algorithms above. I will choose XGboost as the model to fine tune as it is very efficient and portable toward the future.
I will us GridsearchCV to iterate over the XGBoost Algorithm and test different tuning parameters.
Unfortunately, I will not be able to show a visual on untrained data as I used the entire dataset to aid in training to create better predictions for the unknown test set.
However, I can see the results from the Cross-Validation during the GridSearch and look through the best parameters.
Model Evaluation and Validation
After training the model on 144 fits through GridSearch CV. The final results were slightly better than the initial trial of the algorithm and presented the best AUC score thus far.
Best AUC Score:
0.7743
While this score is better than before, I don’t believe it i an excellent result that I would suggest be put into production at a major company. Further data manipulation and study of the features could help.
Best Params:
{'learning_rate': 0.1, 'max_depth': 6, 'n_estimators': 20}Through the GridSearch process, the best results were determined to be those above.
- Learning rate — Of the options this learning rate was not the smallest, but quite low. In this case adjusting the weights in each iteration in smaller movements performed better. Perhaps the others over-corrected and could not find the optimal loss.
- Max Depth — This parameter allowed our Tree algorithm to reach a max depth higher than others in the the gridSearch. Suggesting more complication was slightly better. Perhaps because the data contains so many features.
- n_estimators — Counter to my thoughts, the model performed best with lower estimators than other trials. This allows the “boosted” weak learners to grow, but not too far. Perhaps larger
n_estimatorstrials were Overfitting.
All Params:
{'cv': 4, 'error_score': nan,
'estimator__objective': 'binary:logistic', 'estimator__use_label_encoder': False,
'estimator__base_score': None,
'estimator__booster': None,
'estimator__colsample_bylevel': None, 'estimator__colsample_bynode': None,
'estimator__colsample_bytree': None,
'estimator__gamma': None,
'estimator__gpu_id': None,
'estimator__importance_type': 'gain', 'estimator__interaction_constraints': None, 'estimator__learning_rate': None,
'estimator__max_delta_step': 5,
'estimator__max_depth': None,
'estimator__min_child_weight': None,
'estimator__missing': nan,
'estimator__monotone_constraints': None,
'estimator__n_estimators': 20,
'estimator__n_jobs': None,
'estimator__num_parallel_tree': None,
'estimator__random_state': None,
'estimator__reg_alpha': None,
'estimator__reg_lambda': None,
'estimator__scale_pos_weight': 80,
'estimator__subsample': None,
'estimator__tree_method': None,
'estimator__validate_parameters': None,
'estimator__verbosity': None,
'estimator__eval_metric': 'auc',
'estimator': XGBClassifier(base_score=None,
booster=None, colsample_bylevel=None, colsample_bynode=None, colsample_bytree=None, eval_metric='auc', gamma=None, gpu_id=None, importance_type='gain', interaction_constraints=None, learning_rate=None, max_delta_step=5, max_depth=None, min_child_weight=None, missing=nan, monotone_constraints=None, n_estimators=20, n_jobs=None, num_parallel_tree=None, random_state=None, reg_alpha=None, reg_lambda=None, scale_pos_weight=80, subsample=None, tree_method=None, use_label_encoder=False, validate_parameters=None, verbosity=None), 'n_jobs': None, 'param_grid': {'learning_rate': [0.01, 0.1, 0.5, 0.9], 'max_depth': [2, 3, 6],
'n_estimators': [20, 40, 60]},
'pre_dispatch': '2*n_jobs',
'refit': True,
'return_train_score': False,
'scoring': 'roc_auc',
'verbose': 3}
Justification
This project has successfully segmented customer and shown the difference between the general population. The segments and feature understanding would be of great value to a company and would likely reduce costs in marketing spend by reducing the individuals to target.
As mentioned above, making predictions on the propensity to respond with XGBoost is now performing better than others I tested and using GridSearch has helped to increase the perfomance of that by efficiently tuning hyperparameters. We can see from the AUC score that our model is predicting better than random guess and the XGBoost model architecture is very portable and computationally efficient, making it a good choice for further training and use in production. Using this model would likely also reduce marketing wastage while not sacrificing customer response.
Kaggle Competition
After training this grid search model, I have submitted the results on the Test set with unknown responses.
Score: 0.51005
Reflections
This project reminded me that even what might be a simple Data Science problem can get both complex and time consuming quickly and that real world data takes A LOT of analysis and engineering before you ever get to use mathematics to make interesting predictions.
To recap, In this project:
- I explored a large dataset about individuals regarding many aspects of their financial and social life looking for areas to clean and prepare for model training.
- I used Principle Component Analysis to both reduce dimensions for training and highlight explained Variance.
- I segmented the data using K-means cluster centers and compared the volume of users in our customer group to find trends.
- Finally, I trained a prediction model on similar data to predict a propensity to respond to a marketing contact mailing.
Overall this was a fantastic project and is perfectly suited to real work as a data scientist. I’ve been able to use many tried and true methods such as K-Mean and PCA that will be commonly used in data science work. I also enjoyed testing new methods such as K-Pod and Pandas Profiling.
Moving Forward
With more time to continue working on this project I will attempt to use TensorFlow or another neural network based Algorithm. This might create and interesting challenge and could be very portable.
Thanks
Thank you to Udacity and Arvato Financial for creating this challenge and allowing me to work with the data.
